Um dos pilares da observabilidade são os logs que são extremamente importantes para analisar o comportamento da aplicação. Para muitos, os logs (ou a falta deles) são lembrados somente quando ocorre algum problema na aplicação e é necessário identificar a causa raíz. Logs devem formar informações úteis para tomadas de decisão de forma ativa. No entanto, para chegar a este nível, é necessário garantir a qualidade e a persistência dos logs gerados pelas aplicações.
Boas práticas
É muito comum que as aplicações produzam milhões de linhas de logs todos os dias. Em muitos casos estas linhas são dados soltos que geram informações básicas. Geralmente são difíceis de interpretar e não se relacionam com outras informações. Para transformar toda esta massa de dados em informação útil algumas boas práticas podem ser seguidas:
- Os logs podem ser implementados de forma estruturada. Utilizar padrões como JSON ou XML é extremamente útil, considerando que há diversas aplicações que trabalham com ingestão de dados nativa destes formatos. Por conta da baixa verbosidade, JSON acaba sendo o mais indicado.
- Os logs devem fazer sentido: nem tudo precisa ser logado, e o que for logado precisa passar uma mensagem.
- Atenção a dados sensíveis: vazamentos de dados sensíveis podem ser catastróficos para uma empresa, então é necessário selecionar com atenção o que realmente deve ser gravado.
- Capture logs de diversas fontes: se sua aplicação é distribuída, é provável que haja operações em que os dados são correlacionados.
- Centralize, faça a indexação dos logs e crie consultas: juntar dados de várias fontes pode permitir gerar informações para resolução de problemas de forma mais efetiva, assim como criar insumo para tomadas de decisões estratégicas.
- Otimize a retenção: fazer uma análise sobre o tempo de retenção dos logs é vital para tratar questões de negócio, assim como, reduzir custos.
Os 5Ws
O princípio dos 5Ws ajuda a guiar o pensamento do desenvolvedor na composição da informação do log. Para isso é feito o uso das palavras:
- When: Quando o evento de log ocorreu?
- Who: Quem causou este evento?
- What: O que foi feito que gerou este evento?
- Where: Onde este evento ocorreu?
- Why: Por que este evento ocorreu? Por qual motivo este log existe?
Exemplo:
{
"timestamp": 1657924305, //when
"userid": "227c9aea-048e-11ed-b939-0242ac120002", //who
"message": { //what
"method": "GET",
"uri": "/orders/100",
"response": {
"body": null,
"status": 404
}
},
"servername": "vm-orders-0001" //where
}Respondendo ao “why”, este log existe para registrar a tentativa de um usuário de recuperar um pedido da base de dados. E analisando este fragmento de exemplo, é possível identificar que há uma mensagem sendo passada. A mensagem é:
“O usuário 227c9aea-048e-11ed-b939-0242ac120002, na data de 15 de julho de 2022 as 22:31:45 (UTC) (1657924305), acessou a url /orders/100 no servidor vm-orders-0001 e teve como resultado 404.“
Desta forma o log está estruturado de forma clara e se for feito um relacionamento com a tabela de usuários, por exemplo, é possível identificar o usuário pelo nome e até mesmo prover informações para entrar em contato e tomar alguma ação.
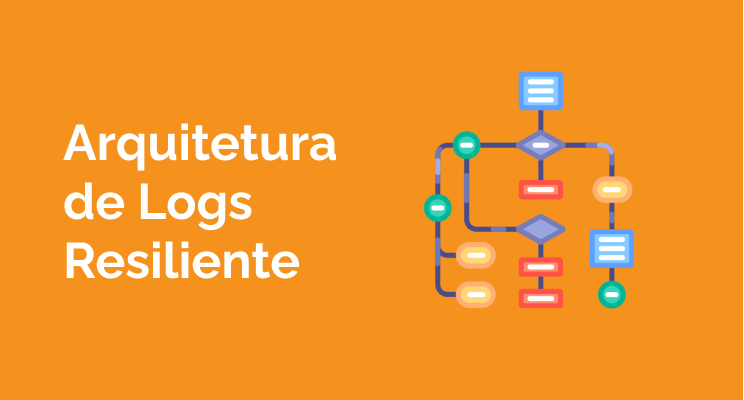
Pensando em um arquitetura resiliente
Com os logs estruturados é necessário pensar em como persisti-los de forma confiável e resiliente, para que seja possível utilizá-los para gerar informações tanto para verificação de problemas quanto para tomadas de decisão.
O diagrama abaixo ilustra os componentes envolvidos em uma arquitetura resiliente.

Observe que a nível de arquitetura há somente os papéis envolvidos em cada parte da solução. Este tipo de diagrama agnóstico possibilita escolher as ferramentas de acordo com necessidades específicas, seja por custos, questões contratuais, requisitos de segurança ou performance.
Saída dos logs
Muitas aplicações geram os logs em um arquivo de texto em um diretório local, ou em um diretório de rede. Mas o que acontece em um cenário em que a aplicação é executada em containers? Containers podem ser criados e destruídos a qualquer momento, e a chance de perder os logs que estão no container é grande. Mapear um volume para os containers pode ser uma estratégia, mas existe uma boa prática no 12-factor que nos diz que “Um app doze-fatores nunca se preocupa com o roteamento ou armazenagem do seu fluxo de saída. Ele não deve tentar escrever ou gerir arquivos de logs. No lugar, cada processo em execução escreve seu próprio fluxo de evento, sem buffer, para o stdout“, sendo assim, uma estratégia a ser adotada é fazer com que a aplicação apenas “lance o log para alguma aplicação capturar”.
Coletor de Dados
A partir deste momento, a complexidade começa a emergir e é necessário que um coletor faça a leitura da saída da aplicação, e se necessário, aplicar transformações adicionais à mensagem e encaminhar esta informação para um ou mais locais.
O coletor pode ser configurado para capturar os logs de novas instâncias da aplicação. Esta abordagem é bem interessante principalmente se a solução for disponibilizada em containers, uma vez que os containers podem ser criados e destruídos a qualquer momento.
Destino dos logs
Os coletores de dados geralmente têm a capacidade de enviar a informação para diversos destinos como bancos de dados, sistemas de mensageria e outros tipos de aplicação. Enviar direto para um banco de dados é uma possibilidade, mas pode limitar o que pode ser feito com estas informações. Uma abordagem interessante, e que ajuda a manter a resiliência da arquitetura dos logs, é enviar as mensagens de evento de logs para um sistema de mensageria. A vantagem desta abordagem é que estes eventos se tornam disponíveis para diversas aplicações. Uma única mensagem de evento de log pode ser gravada em um indexador, ao mesmo tempo que pode ser usada para manter uma base de dados analíticos.
Consumidores e Destino Final
Os consumidores são responsáveis por capturar as mensagens de evento de log do sistema de mensageria e enviar para um ou mais destinos. Para evitar pontos de falha, é indicado que os consumidores sejam específicos, ou seja, é recomendável ter um consumidor responsável por enviar os dados para uma base de dados analíticos e um outro consumidor responsável por enviar os dados para o indexador, esta abordagem possibilita utilizar as melhores ferramentas para cada cenário.
Exemplo de utilização de tecnologias
Conhecendo os componentes e seus papéis deste tipo de arquitetura resiliente, é possível selecionar as ferramentas que irão compor a solução. O diagrama abaixo é a substituição dos componentes do diagrama de arquitetura por ferramentas.

No diagrama acima, o FluentD é a ferramenta responsável por fazer a leitura da saída padrão (STDOUT) das aplicações e publicar mensagem de evento de log no Kafka. As instâncias do Logstash podem ler os eventos do Kafka e gerar dados no ElasticSearch, Cassandra ou até mesmo outras APIs.
Este diagrama é somente um exemplo, dependendo da necessidade, as ferramentas podem ser substituídas para atender questões de negócio ou requisitos não-funcionais. Por exemplo, se a companhia já tem um contrato do Apache Solr, ela pode substituir o ElasticSearch por esta ferramenta.
Quer alavancar sua carreira como Desenvolvedor(a) .NET?
Opa, aqui é o Luis Felipe (LuisDev), criador do blog LuisDev.
Além de Desenvolvedor .NET Sênior, eu sou instrutor de mais de 700 alunos e também tenho dezenas de mentorados.
Conheça o com mais de 800 video-aulas sobre C# e desenvolvimento de APIs com ASP NET Core, Microsserviços com ASP NET Core, Arquitetura de Software, Computação em Nuvem, SQL, HTML, CSS e JavaScript, JavaScript Intermediário, TypeScript, Desenvolvimento Front-End com Angular, e Desenvolvimento Front-end com React. Diversos mini-cursos disponíveis aos alunos e atualizações gratuitas.
Suporte dedicado, e comunidade de centenas de alunos.
Completo e online, destinado a profissionais que querem dar seu próximo passo em sua carreira como desenvolvedores .NET.
Clique aqui para ter mais informações e garantir sua vaga
Conclusão
Utilizar uma arquitetura de logs de forma resiliente é importante para garantir que os logs sejam persistidos e utilizados de forma a gerar informações para análise e tomadas de decisão. É importante avaliar o esforço e o custo para adotar esta abordagem, pois há uma grande complexidade nesta arquitetura devido a utilização de diversos componentes.

Minha carreira tem sido dedicada a ajudar as empresas a tomarem as melhores decisões estratégicas em arquitetura e desenvolvimento de software.
Sou defensor do código limpo, acredito que sempre pode haver uma solução que pode facilitar o dia-a-dia dos usuários.


