
Você sabe o que é um Service Mesh, e quais principais características? Nesse artigo vamos ver exatamente isso, com um cenário de exemplo e com a análise de diversas características de um Service Mesh e como elas podem contribuir para uma arquitetura mais segura, controlada e observável.
Introdução
Em aplicações corporativas é muito comum que serviços se comuniquem entre si dentro da infraestrutura da companhia. Em alguns casos, esta comunicação é insegura e monitorada, confiando na premissa de que se o serviço está dentro da infraestrutura da companhia, ele é seguro e confiável, logo não existem riscos.
Infelizmente nem sempre isso é uma realidade, já que um serviço mal escrito pode resultar em sobrecarga de outros serviços e causar outros problemas difíceis de detectar.
Um service mesh é uma camada a nível de infraestrutura que fornece funcionalidades para a comunicação entre serviços, Através dele, políticas de tráfego, segurança e observabilidade podem ser definidas para um controle mais eficiente do que está acontecendo dentro da infraestrutura da companhia.
Se você leu o artigo API Gateway: O que é e Principais Características pode estar se perguntando se tanto o service mesh quando o API Gateway fazem o mesma função e qual a diferença entre os dois. Ambos possuem algumas funcionalidades parecidas, porém são ferramentas completamente diferentes. Enquanto o API Gateway atua no tráfego NORTE-SUL (de fora da infraestrutura para dentro) o service mesh atua no tráfego LESTE-OESTE (comunicação entre serviços dentro da mesma infraestrutura).
Caso de uso
Para ilustrar a utilização de um service mesh vamos considerar o cenário de um e-commerce, mais especificamente a finalização de um pedido. Neste cenário hipotético, quando um pedido é submetido, várias ações ocorrem de forma encadeada:
- Análise para verificar se todos os produtos contidos no pedido existem no estoque (Estoque)
- Verificação de segurança do cliente para evitar fraudes (Anti-Fraude)
- Processamento do pagamento do cliente (Faturamento)
- Notificação ao centro de distribuição para fazer a entrega (Distribuição)
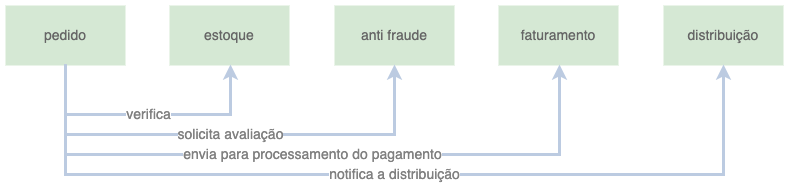
Esta regra pode ser implementada tanto como coreografia, quando os serviços se comunicam através de mensageria ou comunicação direta com a finalidade de continuar o processo, quanto por orquestração, quando um serviço fica responsável por gerenciar o processo entre os outros serviços. Independente da abordagem, ambas farão comunicação entre serviços, e neste momento a utilização de um service mesh será interessante para controlar os serviços.
Para este cenário vamos considerar que foi utilizada uma saga orquestrada realizada pelo Pedido. A titulo de curiosidade, uma saga é uma sequência de ações entre serviços que quando concluídas com sucesso, executam a ação seguinte até o final do processo. Caso ocorra uma falha no processo, as ações anteriores devem ser desfeitas por ações de compensação.
Arquitetura do service mesh
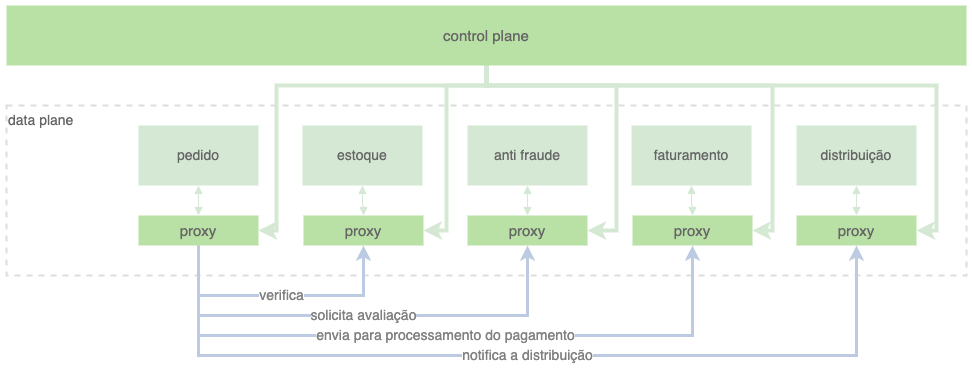
Para executar o controle dos serviços, uma aplicação proxy é adicionada pelo service mesh para intermediar as comunicações com o serviço, esta aplicação é conhecida como data plane. O data plane é quem aplica as políticas que determinam o comportamento das requisições que estão entrando ou saindo do serviço.
Os data planes são criados a partir de um outro serviço chamado control plane.
Exemplificando, se for necessário criar uma restrição de segurança para um serviço, esta regra é criada no control plane que aplica esta regra a todos os data planes correspondentes. Todos os serviços do service mesh se comunicam através dos proxies do data plane.
Controle de Tráfego
A função mais comum do service mesh é o controle de tráfego entre os serviços. Através deste controle é possível definir regras de destino, fazer roteamento a serviços baseados em parâmetros, controlar a saída a serviços externos, além de adicionar resiliência a aplicação sem a necessidade de implementação de código.
Roteamento entre serviços internos
Considerando que o Pedido é o serviço responsável por orquestrar a saga de criação de um pedido, podem ser criadas regras que determinem que somente o Pedido possa chamar estes serviços. Desta forma, é possível fechar comunicações indevidas, evitando possível falhas de processo.
Roteamento para serviços externos
Se os serviços da malha tiverem a necessidade de se conectar a serviços externos, é possível criar regras dentro do service mesh para tratar estas requisições. Uma vantagem de fazer isso é a possibilidade de permitir somente conexões conhecidas.
No cenário do Pedido, o serviço que faz o trabalho de anti-fraude pode ser externo. Neste caso, uma regra pode ser criada dentro do service mesh determinando que se o host anti-fraude.services.com for requisitado por um dos serviços da malha, a requisição ser roteada externamente. Uma outra vantagem deste tipo de roteamento é que podem ser coletados dados de observabilidade em relação a comunicação com este serviço.
Retry
A comunicação entre serviços nem sempre ocorre com sucesso, seja por indisponibilidade temporária do serviço, seja por falha na resolução do DNS, ou mesmo falha em serviços dependentes. Em alguns casos, é interessante tentar executar a operação novamente para conseguir sucesso.
A política de retry informa ao proxy que uma nova tentativa deve ser feita por um número determinado de vezes até que se obtenha sucesso. Um serviço pode chamar o outro uma única vez, o proxy fica responsável por intermediar esta comunicação, validar a resposta do outro serviço e tentar novamente caso necessário. Se uma próxima tentativa ocorre com sucesso, o proxy encaminha a resposta ao serviço.
Imagine que o serviço Pedido fez uma requisição ao serviço Anti-fraude e na primeira tentativa ocorreu uma falha. Como o processo está em uma saga, todas as chamadas anteriores seriam desfeitas. Mas, pode ser que naquele momento, o serviço estava indisponível e uma segunda tentativa seria bem-sucedida. Se um retry for configurado, o Pedido pode tentar chamar o serviço Anti-fraude algumas vezes e conseguir realizar a operação, evitando a necessidade de desfazer as operações anteriores.
Para alguns service meshes o retry pode ser configurado levando em consideração um número de tentativas ou um tempo de tentativa entre uma chamada e outra.
Circuit Breaker
Em um cenário com diversas instâncias de um serviço, pode acontecer que nem todas elas estejam funcionando de forma adequada. Se um serviço tiver 5 instâncias sendo executadas, com balanceamento de carga igual entre elas e uma destas instâncias estiver com falha, 20% das requisições estarão comprometidas. O circuit breaker ajuda a diminuir os impactos deste problema.
O circuit breaker é responsável por desabilitar temporariamente (open) o tráfego para as instâncias do serviço que estão apresentando algum tipo de falha. Depois de um tempo desabilitado, o circuit breaker entra no estado de half open onde algumas requisições são enviadas para aquela instância novamente. Se estas requisições forem concluídas com sucesso, o circuit breaker entra em estado de closed e a operação volta ao normal. Considerando que o tráfego é interrompido para a instância problemática, o balanceamento de carga é feito entre as 4 instâncias durante aquele período.
Em muitos cenários é comum configurar o circuit breaker junto ao retry para aumentar as chances de entrega da resposta ao cliente.
No exemplo da saga de pedido é interessante que o circuit breaker esteja configurado junto ao retry para desabilitar o tráfego para instâncias não saudáveis.
Timeout
Se um serviço demorar para responder, pode impactar tanto os negócios da companhia quanto também a infraestrutura. Para evitar estes problemas, o timeout pode ser configurado para evitar que um serviço ocupe a conexão além de um determinado tempo. Ao alcançar o tempo estabelecido, o proxy automaticamente encerra a conexão. Este recurso precisa ser utilizado com muito cuidado, pois um valor definido de forma equivocada pode fazer com que requisições com potencial sucesso, sejam finalizadas prematuramente.
Fault injection
A injeção de falhas é um recurso interessante do service mesh para validar como o ambiente se comporta quando uma falha ocorre no ambiente. É possível testar o que ocorre quando esporadicamente ocorre um erro 500 na aplicação que está sendo chamada ou quando há uma requisição com tempo de resposta alto. Com este recurso é possível validar as políticas de timeout, retry e circuit breaker.
Load Balance
O load balance (balanceamento de carga) pode ser feito entre as instâncias do serviço usando algoritmos específicos, como ROUND ROBIN, RANDOM, HASH, entre outros. Este recurso permite uma utilização otimizada dos serviços.
Quando há um cenário de deployment blue-green, onde há duas versões do serviço sendo executadas, o load balancer ajudará a distribuir o tráfego entre os serviços.
Se uma nova versão do serviço Estoque for disponibilizada, é interessante direcionar o tráfego aos poucos para ela. Desta forma, o load balancer pode ser configurado para enviar 5% do tráfego para a versão nova. Se a observabilidade apontar que esta nova versão está saudável, a quantidade pode ser aumentada de forma gradativa até que 100% das requisições estejam direcionadas para a nova versão.
Este tipo de abordagem é interessante, pois permite que novas versões sejam implantadas de modo gradual com baixo risco de indisponibilidade do ambiente.
Segurança
Mesmo que os serviços estejam dentro da mesma companhia é importante que a comunicação entre eles seja feita de forma segura. Saber qual serviço executou tal ação ajuda a identificar problemas complexos, além de garantir que os serviços só acessem o que foi acordado. Além disso é importante que o canal de comunicação entre os serviços esteja seguro, uma vez que em um ambiente de sistema distribuído há a chance de ter um intruso que capture as informações no caminho.
Autenticação
A responsabilidade de autenticação pode ser delegada ao service mesh, removendo a necessidade desta validação ser feita pela aplicação. Se uma aplicação dentro do service mesh tenta acessar um serviço ao qual não deveria ter acesso, será barrada automaticamente.
De acordo com a solução proposta o Pedido pode utilizar um token para acessar os demais serviços. Caso o serviço de Distribuição tente acessar o Estoque por exemplo, ele teria de ter um token para isso, ou a sua conexão seria negada. Em empresas com poucos times, o controle dos serviços geralmente é simples e os acessos são acordados e respeitados na maioria das vezes. Em companhias com centenas de times, permitir somente requisições autenticadas é uma forma de garantir a integridade da aplicação.
Autorização
Uma vez autenticado o serviço poderá executar algumas ações no outro serviço, mas nem sempre todas as ações devem estar disponíveis para ele. O service mesh possui recursos para autorizar somente algumas ações por serviço.
Imagine que o Estoque possui um endpoint responsável por fazer a adição de itens, e por uma implementação incorreta, o serviço de Pedido passa a adicionar itens ao Estoque quando ocorre uma falha no processo. Isso poderia causar uma problema enorme pois a companhia estaria vendendo uma quantidade maior do que tem. Neste caso, o Pedido pode acessar o serviço do Estoque porém não deve ser autorizado a utilizar este endpoint.
TLS Mútuo
Uma forma de criar um canal seguro entre os serviços é ativar o TLS Mútuo no service mesh. Desta forma, todos os serviços passam a ter um certificado TLS diretamente no proxy. Pode parecer exagerado, mas se considerarmos que os serviços podem estar em máquinas separadas na nuvem pode haver uma aplicação maliciosa que intercepte esta comunicação e roube este dados.
Observabilidade
É possível controlar o tráfego e aplicar segurança às nossas aplicações, mas é necessário também saber se de fato estas configurações estão funcionando. Além disso, se a saga do Pedido pára de funcionar, como será possível identificar onde a falha ocorreu? Para isso o service mesh fornece recursos de observabilidade, gerando dados para serem consolidados em outras aplicações.
Logs
O proxy pode ser configurado para emitir informações sobre as requisições que estão sendo direcionadas ao serviço. Estes dados pode ser gerados direto no stdout, conforme a recomendação do 12 Factor, e coletados por outra aplicação.
Se o serviço de Pedido está recebendo erro de status code 500 do serviço de distribuição, os logs podem ser consultados para identificar o problema.
Métricas
Métricas são de extrema importância quando o service mesh está ativo, uma vez que como há um novo componente intermediando a comunicação é importante saber quanto dos recursos (cpu, memória e rede) estão sendo consumidos, além de identificar o tempo de resposta do proxy e do serviço de destino. O service mesh gera estes dados em formato time series e envia para outras aplicações para análise.
O proxy deve ter o menor tempo de latência possível e as métricas ajudam a identificar se os recursos estão sendo usados de forma eficiente ou se precisam de algum ajuste fino.
Tracing
Pelo fato da comunicação entre os serviços ser feita totalmente através de proxies, o service mesh gera dados de tracing das comunicações de forma transparente. Este recurso é importante pois ajuda a identificar aonde está o ponto de falha de um processo, além de identificar tempos de resposta inadequados.
No caso da saga do Pedido, quem inicia a saga recebe o código de erro 500, mas somente através de tracing é possível identificar em qual dos serviços que ocorreu o problema.
Insights de Ferramentas
Há um site bem interessante que faz comparação de service meshes, onde é possível ter uma noção das funcionalidades disponíveis para cada um.
Quer alavancar sua carreira como Desenvolvedor(a) .NET?
Opa, aqui é o Luis Felipe (LuisDev), criador do blog LuisDev.
Além de Desenvolvedor .NET Sênior, eu sou instrutor de mais de 700 alunos e também tenho dezenas de mentorados.
Conheça o com mais de 800 video-aulas sobre C# e desenvolvimento de APIs com ASP NET Core, Microsserviços com ASP NET Core, Arquitetura de Software, Computação em Nuvem, SQL, HTML, CSS e JavaScript, JavaScript Intermediário, TypeScript, Desenvolvimento Front-End com Angular, e Desenvolvimento Front-end com React. Diversos mini-cursos disponíveis aos alunos e atualizações gratuitas.
Suporte dedicado, e comunidade de centenas de alunos.
Completo e online, destinado a profissionais que querem dar seu próximo passo em sua carreira como desenvolvedores .NET.
Clique aqui para ter mais informações e garantir sua vaga
Conclusão
Utilizar um service mesh para controle, segurança e observabilidade das aplicações pode ser uma estratégia interessante pois reduz a quantidade de código escrito. Por outro lado, deve ser considerado que uma nova camada será adicionada à comunicação, o que pode aumentar um pouco o tempo de resposta além de ser um possível ponto de falha.

Minha carreira tem sido dedicada a ajudar as empresas a tomarem as melhores decisões estratégicas em arquitetura e desenvolvimento de software.
Sou defensor do código limpo, acredito que sempre pode haver uma solução que pode facilitar o dia-a-dia dos usuários.


